
Introduction
Today, automatic high availability (HA) systems are offered by many software servers solutions. The list of software solutions is not short, and many cloud-based products include this mechanism by default. What about databases? Well, this can be a bit more complicated than other systems. But they are not impossible. In fact, some non-relational databases offer multi-master mechanisms out of the box, but due to the transactional nature implied in relational databases, it requires special attention to avoid major problems such as denial of service or data loss. As for Postgres, it is becoming more popular every year and each new version releases comes with many new features , but it does not include any automatic system for high availability. Nevertheless, it comes with pg_basebackup, streaming replication, logical replication, and pg_promote to give us some tools that come in handy when used with the right external software solution.
In this post, let’s explore what should be taken into consideration when including a HA solution.
Reasons to include or change your automatic system
The main reason to include an automatic HA system is that performing a manual recovery or a manual replica promotion is slow, reduces business availability, and costs money.
The main reason to replace your old system is if your current system can not accomplish what is expected from an automatic system. I.e: failure to bootstrap new cluster members, failure to elect the new leader, missing consensus, split brains, and flapping failovers, among others.
If we stop here and just review the aforementioned issues, all of them are related to communication issues in the HA solution, this is why communication is key here. Let’s see how improving this aspect will enhance the automatic HA system.
Selected Technologies
In recent years, Patroni has become the preferred tool for many DBAs to include in the Postgres ecosystem as the HA solution. What makes Patroni different from other HA solutions is the Patroni external consensus database design, using a Distributed Consensus Store, and its awareness of the Postgres cluster health and member status by querying this store. As indicated, the Patroni communication makes it a good solution. Moreover, Patroni supports a variety of distributed configuration stores (DCS) like ZooKeeper, etcd, Consul or Kubernetes.
In this session, we have selected Consul from the DCS options because it offers features that could potentially enhance our cluster setup. It also avoids the inclusion of additional layers in our architecture, which could be beneficial in some cases. Furthermore, it could be a suitable choice when a solution outside Kubernetes is required.
Quantity matters
Sometimes, architectures are designed by using a smaller number of instances than required, because of the unfortunate belief that more servers imply more maintenance, or that an even number of instances save money, or other reasons.
The truth is that HA systems are designed to support failure tolerance and require specific patterns to accomplish the tasks. For example, a Consul Cluster requires at least 2 members alive to keep the consensus system working in the event of a server failure of any of its members. Why is it important to consider this detail? If the Consul cluster loses its quorum, Patroni will lose its consensus and trigger the safe mode mechanism by closing the Patroni Leader’s writes. The Patroni-Postgres cluster will not perform any failover and the Leader will be in ReadOnly mode. Therefore, having 3 Consul members (servers) in the cluster will tolerate the failure of only 1 server, if one more server fails the consensus is lost.
For the DCS, it is recommended at least 5 servers for a standard production deployment to maintain a minimum failure tolerance of 2. It is also recommended to maintain a cluster with an odd number of nodes to avoid voting stalemates.
Deploying Consul or Patroni on a single server for production use is strongly discouraged due to the significant risk of data loss in failure scenarios. In single-node setups, there is no redundancy or failover capability, which are critical components of high availability (HA) systems. Relying on a single node means that if it goes down, there’s no backup, and the system could suffer severe downtime or data loss. Deploying Patroni on a single node defeats the purpose of using HA software.
Moreover, engineers sometimes update configurations only within the Distributed Configuration Store (DCS) without saving those changes elsewhere. This is risky because if the DCS experiences a failure, any non-persisted changes could be lost.
In production environments, it’s essential to deploy these systems in a multi-node configuration to achieve true high availability and data resilience. Additionally, always ensure that changes made in the DCS are properly versioned and stored outside the cluster to prevent configuration drift and ensure consistency across environments.
Architecture Design
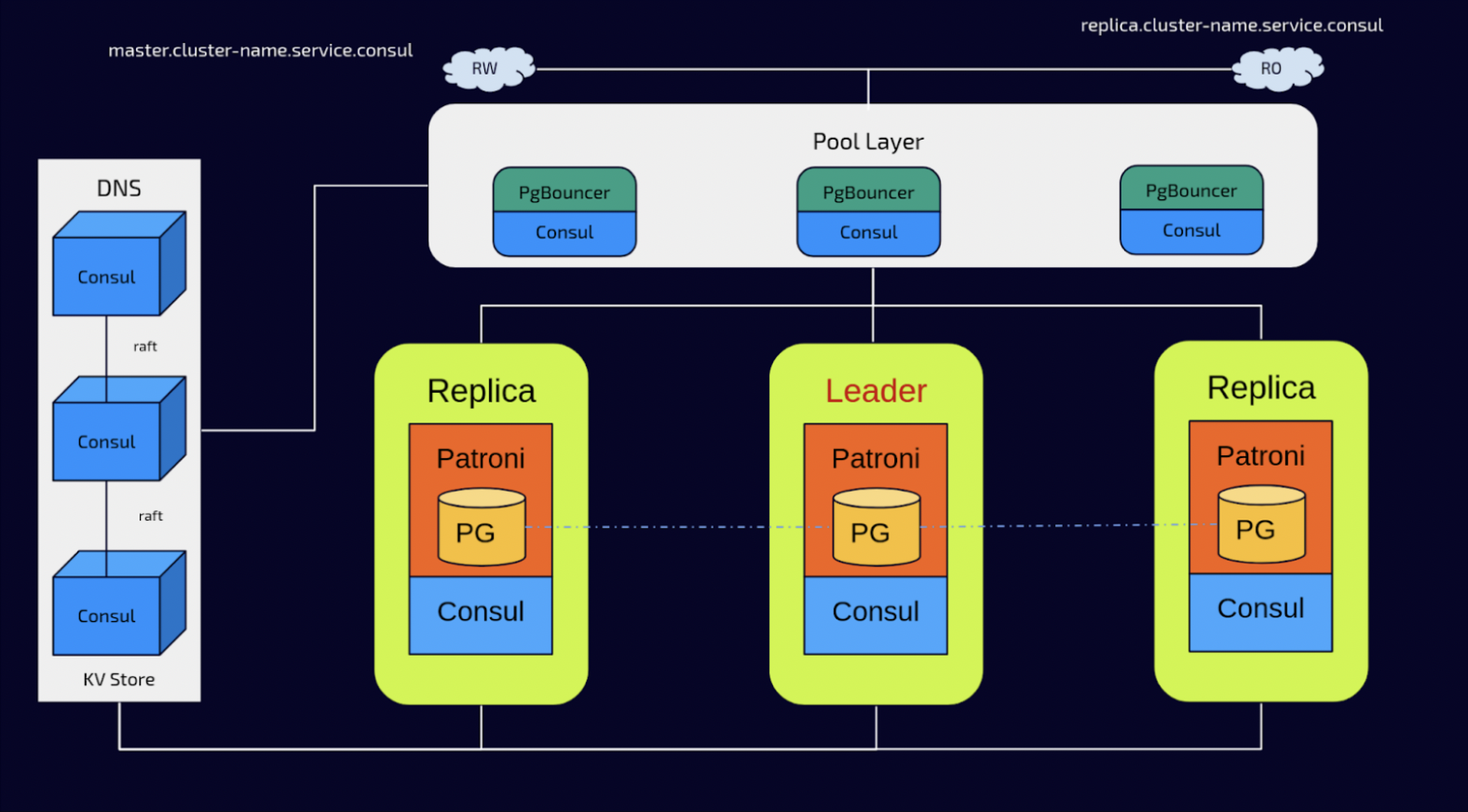
The diagram above shows the full architecture setup for an automatic HA system.
Despite not being required, our take on the Consul setup is to install the agent locally on each host in the architecture. Consul could be installed in the Patroni nodes forming the Consul Server Cluster and use the same resources, but a question arises. What if one Patroni server goes down? The consensus layer will survive, if you lose two Patroni servers you will lose the DCS and Patroni will set the unique Postgres server alive as read-only. This is a Patroni security mechanism to avoid data loss. Aside from this, piling up several technologies responsible for the core system mission is not a good practice since sharing hardware resources could affect the server’s performance. These are the reasons why the Consul server cluster is installed in dedicated hosts.
The Consul server cluster has been enhanced with a high-availability solution based on the Raft consensus algorithm, thereby ensuring the DCS layer is capable of tolerating faults.
When the Patroni cluster is created, it registers the cluster members and their role in the DCS. At the same time, it creates a service name for the Leader member and another for the replicas. These NS records can be queried by using the DNS service available in Consul, which, of course, should be properly enabled. In this way Patroni has broader information about the cluster members, roles, and health status since Patroni performs health checks on its members and likewise Consul over its agents (clients).
Remember that Patroni now controls the Postgres service and configuration files by reviewing and updating the DCS, if required, knowing the roles, cluster topology, changes in the Postgres configuration, required restarts, and pending maintenance jobs.
Now that a Consul service with fault tolerance and high availability is available, we can take advantage of the DNS service and use these entries to connect the pool layer.
In the pool layer, PGBouncer is provided to handle client connections. As indicated in the previous paragraph, the name services managed by Patroni and available by the Consul DNS service are used to connect the PGBouncers to the correct Patroni member. The name service will always be updated when switchover or failover in the event of a member failure, as well as member exclusion from the group.
Remote Cluster
Patroni has been developed with the inclusion of the Standby Cluster feature. This feature comprises the generation of a replica that is not integrated into the primary Patroni Cluster. The Standby Cluster is established as a new independent cluster and is capable of maintaining its replicas, which then become part of the cascade replication process. This feature provides the capability to set external clusters for disaster recovery events.
Architecture design
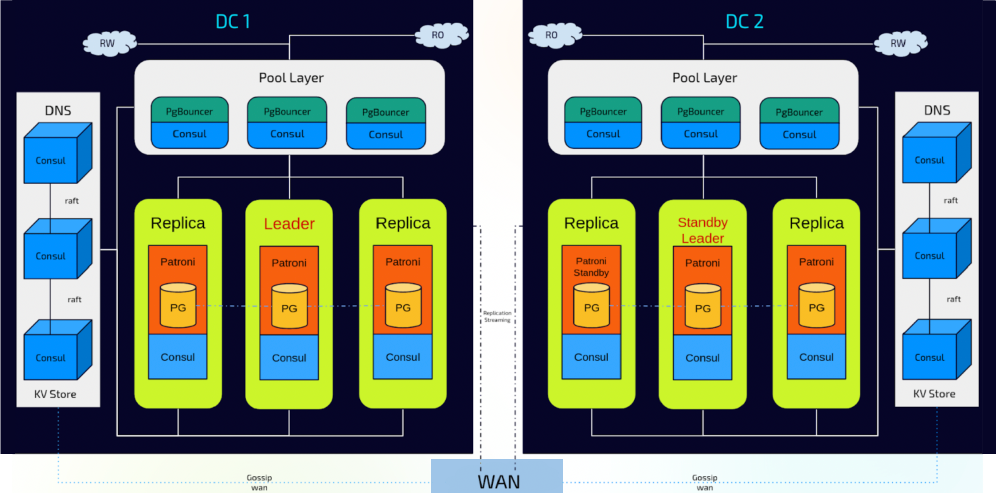
It is recommended that the DR Patroni cluster be identical to the main cluster in terms of capacity, hardware, software versions, and minimal details. It is essential that a secure network connection is established between the two clusters.
Setting up the Patroni Standby Cluster does not differ very much from the Main Cluster. However, there is a detail about setting the replication connection. Patroni has the host: key available in the configuration file and the Patroni Leader address should be added as the value to properly set up the replication streaming. What is going to happen when the Leader-member is demoted? The Standby replica will lose the connection and the track of the changes, the DR cluster will require to be recreated. At this point, the DR site can not guarantee data endurance. We don’t want to bootstrap a 5TB database size each time a failover occurs either.
Here Consul plays an important role because it supports mounting federated clusters.
The Main Consul cluster holds communication with the federated cluster using the Gossip protocol. This protocol is configured by default to support poor WAN connections, therefore there is no need for tuning Consul. The Federation in Consul is not a full replication of the DCS, (it can be enabled by using other methods) instead it just sends to the federated cluster basic information about the main Patroni Cluster, and basically when the data is queried by the Patroni Standby cluster or Consul Federated via the gossip protocol.
Now that our Main Consul can be reached by the Federated one, it is possible to query the Main Consul for the Main Patroni Leader service name by DNS upstream. This feature enables the mechanism for the Standby replica to use the NS entry instead of the IP address adding full support for an automatic HA DR system on any remote DC. Also, the Consul Cluster provides the name services for the Standby Leader and its member replicas, therefore it can be used to query de Standby cluster in the remote DC if needed.
Following the right steps, commuting from one DC to another is just a task of seconds. Of course, avoiding manual intervention is strongly suggested to perform these major maintenance tasks.
Conclusion
Setting up the right high availability system is challenging and fun, and a lot of learnings can be acquired in the development process.
Patroni and Consul demonstrate how important it is to improve the communication in your High Availability solution system since the cluster stability depends on it. A list of suggestions was reviewed to avoid issues in the HA setup.
Also, we see that Patroni limits are not only for local setups, you can improve your architecture setup and create a DR site.
Using the right software tools to improve your HA system is doable today without paying big bills, it requires the tools that better suit your requirements. At the same time, your on-premises Postgres clusters can measure up to the Cloud HA solutions.
The Next post will drive you to the hands-on local Sandbox with the needed configuration files to accomplish the described architecture, stay tuned!


